On October 23, 2025, the Whiting School of Engineering at Johns Hopkins University welcomed Aaron Roth, a professor of computer and cognitive science at the University of Pennsylvania. Roth delivered a presentation titled “Agreement and Alignment for Human-AI Collaboration,” which explored innovative frameworks for improving interactions between artificial intelligence and human decision-making.
Roth’s talk was anchored in the findings from three pivotal papers: “Tractable Agreement Protocols,” presented at the 2025 ACM Symposium on Theory of Computing, “Collaborative Prediction: Tractable Information Aggregation via Agreement,” and “Emergent Alignment from Competition.” These studies delve into how AI can enhance human decision-making, particularly in critical areas like healthcare.
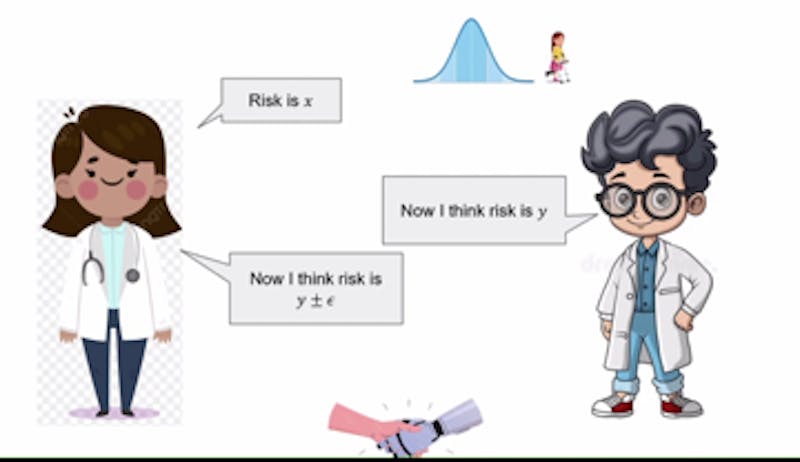
One of Roth’s key examples involved AI assisting physicians in diagnosing patients. In this scenario, the AI would generate predictions based on historical data, such as past diagnoses and various symptoms. The human doctor would then evaluate these predictions, using their expertise to agree or disagree based on their understanding of the patient. Roth explained that when disagreements arise, both parties can refine their viewpoints over several rounds of discussion, ultimately reaching a consensus.
This iterative process relies on a concept known as a common prior. This principle suggests that both the AI and the doctor start with shared foundational assumptions about the world, despite possessing different pieces of evidence. Roth described this dynamic as Perfect Bayesian Rationality, where both parties understand the other’s knowledge without knowing the exact details.
Yet, Roth acknowledged the inherent challenges of achieving such agreement. Establishing a common prior can be complex, especially when dealing with multifaceted issues like hospital diagnostic codes. As the discussion evolved, Roth introduced the idea of calibration, using it as a framework to facilitate better agreements.
Calibration, according to Roth, can be illustrated through the concept of forecasting, such as predicting weather conditions. “You can design tests to determine if the forecasts align with true probabilities,” he explained. This concept extends to conversations between the doctor and AI, where each party’s claims influence the other’s subsequent predictions. For example, if the AI suggests a 40% risk associated with a treatment and the doctor estimates it at 35%, the next AI prediction would fall between these two figures, aiding in quicker consensus-building.
While the previous scenarios assumed aligned goals between the parties, Roth noted that this is not always the case. In instances where an AI model is developed by a pharmaceutical company, there may be conflicting interests regarding treatment recommendations. Roth advised that in such situations, doctors should consult multiple large language models (LLMs). This approach would enable medical professionals to compare varying perspectives from different companies, ultimately leading to more informed decisions.
Roth emphasized that market competition among LLM providers could drive improvements in model alignment and reduce biases. As each company strives to present the most convincing model, the overall quality of AI systems could improve, fostering better outcomes in medical contexts.
Towards the end of his presentation, Roth addressed the concept of real probabilities—those that accurately reflect the complexities of the world. He noted that while precise probabilities are ideal, they are not always necessary. Instead, it is often adequate for probabilities to remain unbiased under certain conditions. By leveraging data effectively, AI and human collaboration can yield reliable insights for diagnoses, treatments, and other critical decisions.
In summary, Roth’s insights underline the potential for enhanced collaboration between humans and AI. By refining how these two entities interact, particularly in healthcare, there is an opportunity to improve decision-making processes significantly.